Underappreciated Superpower: a look into useful software tests
- Intro
- First-class citizen
- Structuring a test
- Structuring tests
- New features
- Fixing bugs
- Naming tests
- UI Testing
- Benefits
- Outro
Intro
In my opinion, it wouldn’t be outrageous to claim that tests are the most important part of the code you write.
This is a part that helps you clarify, specify, and enforce the (correct) behaviour of the code. In 90% of the cases, I would rather have a detailed description of the behaviour that the code should exude rather than the code itself if it is presented as a black-box.
While some might think that it’s the actual code that does the work and thus it should be the only piece that actually matters, I’ll say that I have yet to find a program of a non-trivial size that hasn’t changed after it was first written. Making changes should be easy and I shouldn’t break existing functionality.
Having a detailed specification and examples in a way that’s automatically enforced, lets you do some ambitious updates to the code like:
- removing subcomponents
- replacing algorithms
- optimizing code
- etc
Somebody will claim that you can do that anytime. But how many of us have heard arguments like “if we change X we will need retest the whole Y so lets not do it”?
Writing tests is the best way to describe what the code should do. It can be enforced automatically and effortlessly after it’s checked into your CI.
Also, please pay attention to the fact that I am not talking about the tests as a way to ensure that there are no bugs. Tests can’t really give you any guarantees here.
First-class citizen
Due to the reasons above, I am certain that tests (end-to-end, integration, unit, etc) deserve to be regarded as a first-class citizen in your codebase.
They deserve to be refactored and all of the principles like SOLID should apply as it applies to the regular code.
So whenever you see a code repetition or some other kind of code smell, you should address in the same way as you would do with the code that’s being tested.
Structuring a test
Every test should have 3 major parts:
- Setup
- Execution
- Assertion
For Python, I use the following framework:
with given([
database_is_running(),
server_api_is_running(),
users_are_present(),
]) as context:
with when("users are retrieved"):
users = context.get("/api/users")
with then():
assert_that(users, has_length(greater_than(0)))
The given() context sets up the environment for this specific case. when()
groups the code that’s responsible for “doing” and then finally the then (or resulting())
contains the asserts about the final state.
The test should also:
- be linear with no if-else statements
- contain as little asserts as possible (one assert is recommended)
- contain no loops
- avoid testing intermediate state - only the final outcome should be evaluated
Obviously, there will be exceptions to these rules but it is important to recognize that breaking these rules isn’t ideal and it will make the next developer (including future-you) upset.
Structuring tests
One of the most useful rules, that you should always try following, is packaging by feature .
It would be really strange to read documentation in a way where it describes persistence functionality for all of the features (user, post, transaction), and then it goes to describe how each of that information is displayed and etc. Group your tests by feature.
Next, you will have to choose the right ratio of end-to-end, integration, and unit tests. There are a few things that I would like to emphasize regarding integration and unit tests.
Integration tests
First of all, I favour integration tests over all of the other types of the tests (as long as it makes sense). My proposed ratio of end-to-end, integration, and unit tests would look like this:
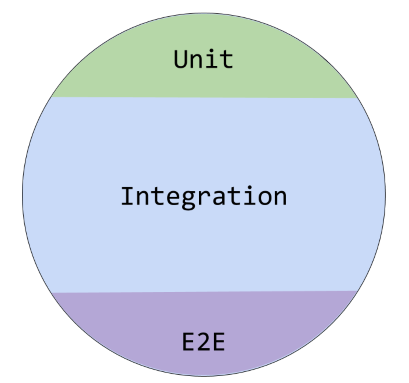
Some of the developers go crazy about mocking out dependencies like the database and other integral parts of the system that I really do not see a point of doing. For example, in most cases a specific database flavour will be used and I believe that you want to know that the software works with that database instead of some mocked interfaces.
In some cases where there is lots of processing done and DB is being called quite often (several thousand times per test) it makes sense to mock it out with some in-memory implementation.
The same goes with almost any external library that you will be using in a project - they shouldn’t be mocked and the actual implementation should be tested. Following this route, most of the projects will end up having way more integration tests.
Unit tests
There should be a fair share of unit tests as well. If there is some feature that’s easy to test as a unit test, then it should be done so. I would even expect that some applications that are not so heavy on CRUD should probably have more unit tests than integration tests.
It is important to point out, that a unit test in reality should really mean “a test for some unit of functionality”. A unit shouldn’t be limited to a function or a class. Quite often it is going be a few classes and functions working together to deliver functionality.
For example, when you are building depth-first search, you shouldn’t be creating separate tests for Tree and Node classes but rather for the functionality itself. Often Java developers will do this by creating TreeTest and NodeTest.
Instead, go with
@Test
public void depth_first_should_return_the_right_path() {
Tree tree = createTree();
Node targetNode = Node.of("City");
Path path = tree.findShortestPath(targetNode);
assertThat(path.toString(), equalTo("London-Berlin-Prague"));
}
End-to-end tests
E2E should be used sparingly. Usually, they require an environment that’s difficult (slow) to prepare and there are a lot of different aspects of the system that can go wrong (break).
If all of your tests end up being as E2E tests it would be reasonable to find that the CI cycle can take hours to complete.
Additionally, since E2E test touches so many aspects of the system (UI, API, database, networking, etc) one small issue can make your entire E2E suite go red. It’s extremely brittle and fixing issues like that is a boring and unproductive endeavor.
However, there is still need for having at least a few tests that can check if the entire system is working. There are a lot of ways that glue-code can fail you. Maybe your memory database is a tad different from the actual system it will be running on. Maybe there is a wrong prefix appended before the RESTful API calls.
We have to watch out for that and even the best mocked out interfaces won’t help to test if different parts of the system interact correctly.
New features
Write a test first. Treat this step as a design phase where you answer the question to yourself: “How I’ll be using this feature as a developer? What kind of APIs I’ll be calling?”.
For example, if it’s a new endpoint to create a user, create a test that has
user = {'email': 'me@localhost'}
user = http.post("/api/users/", user)
assert_that(user['id'], instance_of(str))
and that’s pretty much it.
Hardcore TDD and XP developers will loathe this advice, but do not worry about any tests for any other part of the system just yet. Just implement everything using a bit of common sense to make the test above work.
If there are going to be a few Repository classes (that you needed to create to make the API work) that do not have tests dedicated for them - do not sweat it. Introduce separate tests for those classes when you will be adding functionality specifically for them.
When there is a new aspect to the feature (lets say now we want to delete a user), create a new test and follow a similar pattern
Fixing bugs
The same goes for fixing bugs - write a test first and then fix the bug.
However, I do bug fixing a little bit differently than new features. Whenever I am trying to fix a bug, it is important to capture the problem at the lowest level of the dependency tree.
Let’s say that the new user API doesn’t save the email of the user properly. You would like to fix that. There are multiple layers where you could create a test to capture the problem:
- UI
- Restful API
- Data Access Layer
- Restful API
The rule here is to create a test in a layer where it would depend on as little stuff as possible while still capturing the original issue. Basically, you want to go as deep as you can. If you weren’t escaping the values correctly at the Data Access Layer, that’s where the test should go.
This is also a perfect opportunity to create missing tests for the Repository (that’s the data access layer) that I said you shouldn’t worry about.
Naming tests
As they say, naming things is one of the two hardest things in CS. But actually naming tests well is not that hard. There are a few simple rules that you can follow that will make the names of the tests descriptive and useful.
A great way to start, is to think about Scrum-like story:
As a <type of user>, I want <some goal> so that <some reason>.
It will put us in the mindset of “what do we want to achieve”. So let’s say we would like to create “a login functionality so I could be identified as a returning user and I could browse previously saved products”.
This would cover multiple aspects of the system but now let’s focus on the login itself. Since we would like to have means for users to login, we could just say that:
@Test
void user_should_be_able_to_login_using_rest_api() {
...
}
It doesn’t really matter how you name the class but I usually use classes as a grouping for major features. So here, it could look like:
class LoginFeature {
@Test
void user_should_be_able_to_login_using_rest_api() {
...
}
}
We might realize that there is a specific detail that we have missed, so later we might describe that as well:
@Test
void user_should_get_a_valid_auth_token_upon_request() {
...
}
And that’s it. Tests like these will also act as documentation - just collect the names and dump them into a file. It will contain the description of the ACTUAL behavior of the system.
Also, whenever a test breaks, you won’t have to guess why it checks (asserts) for some specific value of the string. You will be able read what was the indented behavior and you will get the big picture.
UI Testing
Testing User Interfaces is still a pain in the ass. Lots of frameworks for UIs do not take testing seriously and thus tooling often suffers. If that’s the case for the UI framework of your choice, it will mean that you will need substantial initial effort to set up your testing environment.
Also, quite often, if testing is an afterthought, concepts such as Inversion-of-Control are going to be alien to the framework and you will have trouble mocking out non-UI dependencies.
If it’s a trivial project, it’s often easier just to code it an forget. However, if it’s gonna be a >1 developer-month project it’s always worth to invest extra time to set up the testing infrastructure. In the end, you can always run the application and interact with it at the OS level using some automation tools like UiPath. Mocking out dependencies could be done with environment variables and a few ifs.
Getting UI right is often a hard task and never should be taken lightly. Also, it is likely that the UI is going to be one of the parts that are going to change more often. Non-trivial complexity and a huge amount of changes is a recipe for broken functionality.
Benefits
Having a well-designed and maintained test suite is like having superpowers for software development.
All good developers keep constantly learning about the domain they are working in. The abstractions they’ve created in the beginning might seem naive later or just plain wrong and it is going to be extremely useful to refactor them using the new understanding.
A good test-suite is an enabler for change. Even making major refactorings with a good test-suite is a rather easy task thus you are less hampered down with technical debt.
I would even argue that most of the technical debt is the result of the fact that developers are afraid of breaking things. With a good test-suite you can’t really break stuff.
Finally, a properly designed software (after all of those refactorings) makes it really easy to introduce new features. That’s a business-oriented win right here.
Also, properly structured and named tests can act as documentation after doing some post-processing.
Outro
If you still think that the tests are something that only pretentious developers do when they don’t have to worry about shipping features, I would encourage you to drop other useless stuff that doesn’t matter (stuff that users do not see):
- code formatting
- version control
- linters
- continuous delivery
- logging