How my software development has changed in the last 10 years
- Design: Keep It Stupid Simple
- Premature Design
- Avoid inheritance
- Avoid generics
- Functional Programming
- Tests as documentation
- Tests are the first-class part of your codebase
- Refactor often
- Avoid null
This is a continuation of the first part but while in the later I’ve focused more on the whole industry, this time I’ll try to reflect on how my own software development practices changed over time.
If I had to point out one common pattern that I try to adhere to, that would be “just make it simple”. Make simple everything: your code, your CI, DevOps.
I still remember that roughly ~10 years ago while I was still a poor PHP developer,
I’ve written a horrific for-loop. That for-loop abused for(;;) structure
to its limit but it was compact, included several logical statements and so on.
Something like that (a sample from another project)
for (int i = (dealer + 1) % players.size(); playerPositionCounter < players.size(); i = (i + 1) % players.size()) {
...
}
but worse.
Only after it was almost immediately rewritten by a senior developer, it became apparent how bad that was. The new code had more lines, some repeated code, but it was much simpler. The original code would have been impossible to understand in a week, and the new one would be easy to pick up right away even in a year.
There is a lot of value in making your software simple.
Design: Keep It Stupid Simple
Today one important piece of advice that I try to push is to not make code complicated. Make it easy to read. Make it easy to understand.
I believe that all of the SOLID advice boils down to keeping it simple so if you want to take a shortcut here, it’s really easy - just do no try to outsmart yourself and your colleagues.
For example, when Law of Demeter is broken
param1.getA().getB().getC(),
you can see right away that a simpler version paramC could be passed instead and automatically you
start following LoD (while we are here, I’ll add a note that passing Aggregate
is still OK).
In the end, I still sometimes find myself hard to follow this advice. Sometimes the problems being solved are really complex. But sometimes it just reflects my poor understanding of the problem.
Make it easy to read and understand
Most likely, your code is gonna be written once and read many many times.
Code Conventions for the Java Programming Language, have this written:
- 80% of the lifetime cost of a piece of software goes to maintenance.
- Hardly any software is maintained for its whole life by the original author.
- Code conventions improve the readability of the software, allowing engineers to understand new code more quickly and thoroughly.
So do not skimp on the proper structure, variable and function naming.
Instead of
elem = object[2]
do
thirdPlayerInfo = recentlyVisitedPlayers[2]
Unless it’s a scientific or a well-defined domain shorthand for a variable (like v = velocity), always prefer the longer name.
Premature Design
I think I’ve learned to stay away from premature abstractions. I’ll expand on prototyping later but premature optimization is the root of all evil. I believe this holds true for software design as well.
You have to understand that before you start coding and get your hands dirty (with code and business knowledge) you are not qualified to make sound design decisions. So instead of shooting yourself in the foot, leave yourself some flexibility by just implementing the simplest approach that works (that’s a heuristic that works surprisingly well).
That holds true for code (de)duplication as well. Sometimes it’s just a simple string formatter that you can see that will be used in many different places so it’s natural to get it extracted. Sometimes it’s a part of the process that guides some other thing. Things are not so obvious in these cases and straightforward deduplication will turn out to be a pain in the ass to maintain as you will start adding some boolean flags and parameters.
Some code might appear to do the same initially but later you will find that actually, the process is different and unique. However, now you are stuck with a “generalized” solution that isn’t general nor easy to work with.
Quite often people go really crazy with extends and generics only to wind up with a code that’s impossible to work with and doesn’t bear any similarity to the domain.
Avoid inheritance
After spending my fair share amount of time debugging some convoluted inheritance trees with less than appropriate uses of Template (anti-)pattern, I came to prefer Composition-over-Inheritance . You get more code duplication by adding all of those delegation methods, but the straightforwardness, flexibility, and peace of mind that you are not breaking anything, more than compensates for that.
Avoid generics
They can get complex really fast if you don’t keep them in check. You might say “But hey, I am developing a lock-free collections library. I can’t do without generics!”. That’s a fair use case - go ahead. However, if you are in the process of writing some general data abstraction layer that “can be used by other teams as well”, I have bad news for you. You gonna be lucky if actually anybody else besides you read that code and there is no need to commit to generics if you can avoid them.
In a nutshell, you don’t really want to end up with something like this:
public abstract class AbstractMessageLite<
MessageType extends AbstractMessageLite<MessageType, BuilderType>,
BuilderType extends AbstractMessageLite.Builder<MessageType, BuilderType>>
implements MessageLite
In reality, this is just another example of “avoiding premature optimization”.
Functional Programming
I guess my first experience with functional programming was JavaScript. At the time it was really clunky and unrefined (my own approach and tools available). But you could do some currying and cool local function declarations.
But there wasn’t much appreciation until roughly these three things happened:
- I’ve started doing Python,
- I’ve learned RxJava,
- Java 8 was released.
Back in the day, Python ecosystem was one of the first (among major programming languages) to encourage the use of functional programming (all of those enumerates, zips, and yields).
Java 8 made working with functional code in Java much more pleasant. It included the first Stream support and, most importantly, it was possible to write lambdas. Having learned RxJava and its functional paradigm, I’ve started using functional programming quite often.
Functional programming doesn’t really make sense if you are working with a mutating state, thus I’ve adopted immutable collection libraries.
What’s the result? I think my code became more straightforward to follow and there are way less “strange” bugs that are usually caused by deep state updates or some rogue uses of the object. Most of the resulting state is now a result of a pipeline that just processes data.
Obviously, your entire program cannot really be functional and stateless as it will probably won’t solve any meaningful business problem.
My approach here is to use functional programming tactically. The big picture (architecture) of the system is usually built following Domain Driven Design principles, but local code (code in the methods) is usually functional. Here you have to be really pragmatic as approaches available to you will be often guided by the frameworks and libraries you gonna use.
In the end, I still feel noobish in this field and I would like to learn Haskell and/or Clojure in the next few years.
Prototesting
One of the bigger changes happened the way I build, test and design software. Majority of my current code is written as a result of not passing a test. It’s not quite TDD as they want to have no code written that’s not a direct result of making a test pass, but something not far from that.
First of all, whenever I am building APIs, I just write the resulting API interface in the test in the way I would like to use it in a real program. This way you get to play around with the result before the actual code is designed.
After you end up with the code that would make you happy to use, you just autocomplete and fill in the gaps to make the test pass.
Later, when there is a new use case, some twist, or something that you missed - just add as a new example/testcase.
This way most of the tests are basically integration tests, but that’s the way I like it now. Unit tests are often useless as they do not capture intricate interactions between different components of the system. In the end, instead of your regular pyramid, you get
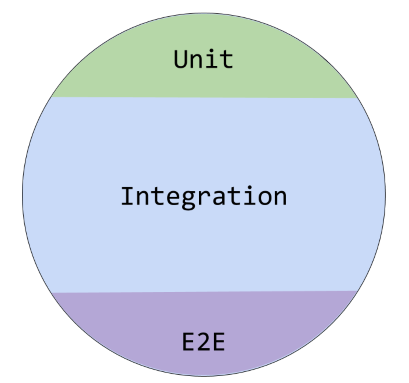
In a regular pyramid, most of the code ends up testing the implementation instead of the behavior. However, I am not completely against unit-testing as it has its own place. Usually, all of the highly specialized and complex functions deserve to have unit tests (for example, email validation regexes :) ).
Tests as documentation
Whenever I write tests now, I describe the wanted behavior in the test (somebody calls it BDD). It’s rather straightforward. Instead of having
@Test
void test2() {
...
}
write
@Test
public void node_id_cards_should_apply_reverse_replacement_when_there_are_multiple_replacements() {
...
}
This way your tests will act as documentation whenever you come back to the project.
Tests are the first-class part of your codebase
Another thing that I’ve realized is that tests are the first-class members of your codebase.
Treating your tests as some supplementary code is a sure way to shoot yourself in a foot. Tests need to be maintained, updated, and refactored with the rest of the code.
If you are not going to spend time creating a pleasant testing environment, then testing won’t happen because it just gonna be too difficult to write tests. It’s going to get more and more difficult every time you skip on creating or updating data preparation script or environment setup.
These days there are few excuses left not to have a proper testing environment when you have Docker, Vagrant, and docker-compose.
Refactor often
When there is a comprehensive test suite watching your back, it is extremely easy to refactor code. If tests aren’t over-engineered and if they focus on the behavior, there shouldn’t be any problems following through with major refactorings.
Making big refactorings with ease has some major quality benefits to the codebase. Before, I’ve claimed that you won’t probably have enough domain expertise to design the system properly. But that is not a problem anymore as your design will evolve to match your ever-increasing understanding of the domain. Fewer discrepancies between your code and domain ~ fewer bugs and easier maintenance.
More OOP
I’ve found myself using way more objects and classes. Every time there is a new concept, I try to introduce a class for it. Capture it explicitly.
For example, if there is a specific format for a player ID, then create it. Next time you use it in the Map, it is gonna be much clearer:
Map<PlayerId, Player> idToPlayer = Maps.newHashMap();
And now, instead of upsetting your production environment with some random string, you will make the compiler complain about that right away. Additionally, you will be able to add validation “for-free” just by updating the constructor.
Also, whenever I feel that I want to create a private method, I always consider if it should be a separate class instead. Lots of private methods is a strong smell that your classes are trying to do too much.
Avoid null
Somebody called “null” the billion dollar mistake. These days I wholeheartedly agree with that. Avoid them by using Optional (most of the modern languages have similar alternatives) or Null-Object.
My database is just a detail
I used to start my system design with a database schema design. Tables, foreign-keys, some normalization and you get a solid database structure design that you can build your software for.
After adopting DDD a while ago and after having deployed a system using EventSourcing and CQRS, it made me realize that the database is just a detail. An important detail, but still - just a detail.
These days database for me might as well be just a plain text file. It doesn’t really matter. As all of the persistence will be abstracted away by Repositories. What only matters is that the state can be persisted and retrieved intact.
Also, not every Object deserves its own table or collection, so it is important to decide what is a:
- Value Object
- Entity
- Aggregate
Usually, only Aggregates deserve to have a Repository for persistence.
If you feel that you couldn’t live without advanced SQL queries, consider this: how much it would take to query aggregate(s) on/after write, process, transform, and dump (or not) it into a specific table that would act basically as a view?
I am not saying that SQL is evil but people depend too much on the database capabilities. Quite often, they let the database-centric mindset creep in and compromise their domain model (I certainly used to be guilty of this).
Outro
I feel that at this point it’s already quite a bit for the reader and it’s quite tiring to write up everything thoughtfully. I haven’t touched topics such as frontend development or DevOps which could be interesting.
I hope that some of the engineers are going to relate to my experience and that maybe some of you are going to find this helpful (all those links and tips :) ).